第 18 章 发布与订阅
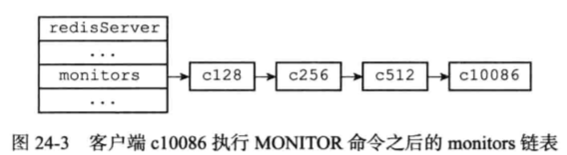
在Redis中,客户端可以订阅一个或多个频道,之后其他客户端往这个频道发送消息时,所有订阅者都可以收到这条消息。 SUBSCRIBE订阅一个频道。 PSUBSCRIBE是订阅一个符合规则的一个或多个频道。 PUBLISH是往频道发布一条消息。 #####频道的订阅与退订 当一个客户端执行SUBSCRIBE命令订阅某个或某些频道的时, Redis将所有频道的订阅关系都保存在redisServer的pubsub_channels字典里面,这个字典的键是某个被订阅的频道,而键的值则是一个链表,链表里面记录了所有订阅这个频道的客户端,如下图所示
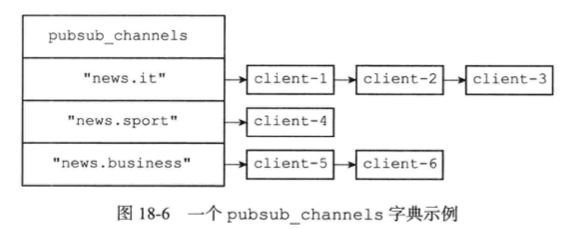
、client-1、client-2、client-3三个客户端正在订阅”news.it”频道。 ·客户端client-4正在订阅”news.sport”频道。 ·client-5和client-6两个客户端正在订阅”news.business”频道。 退订频道 UNSUBSCRIBE命令的行为和SUBSCRIBE命令的行为正好相反,当一个客户端退订某个或某些频道的时候,服务器将在pubsub_channels字典中找到频道对应的订阅者链表,然后从订阅者链表中删除退订客户端的信息。
模式的订阅与退订
服务器将所有频道的订阅关系都保存在服务器状态的pubsub_channels属性里面,与此类似,服务器也将所有模式的订阅关系都保存在服务器状态的pubsub_patterns属性里面,pubsub_patterns属性是一个链表,链表中的每个节点都包含着一个pubsub Pattern结构,这个结构的pattern属性记录了被订阅的模式,而client属性则记录了订阅模式的客户端。 如下图所示: 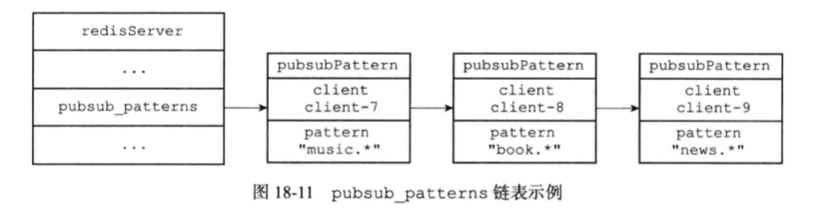
展示了一个pubsub_patterns链表示例,这个链表记录了以下信息: ·客户端client-7正在订阅模式”music.“。 ·客户端client-8正在订阅模式”book.“。 ·客户端client-9正在订阅模式”news.*“。 退订模式 模式的退订命令PUNSUBSCRIBE是PSUBSCRIBE命令的反操作:当一个客户端退订某个或某些模式的时候,服务器将在pubsub_patterns链表中查找并删除那些pattern属性为被退订模式,并且client属性为执行退订命令的客户端的pubsubPattern结构。 发送消息 当一个Redis客户端执行PUBLISH命令将消息message发送给频道channel的时候,服务器需要执行以下两个动作: 1)将消息message发送给channel频道的所有订阅者。 2)如果有一个或多个模式pattern与频道channel相匹配,那么将消息message发送给pattern模式的订阅者。 将消息发送给频道订阅者 因为服务器状态中的pubsub_channels字典记录了所有频道的订阅关系,所以为了将消息发送给channel频道的所有订阅者,PUBLISH命令要做的就是在pubsub_channels字典里找到频道channel的订阅者名单(一个链表),然后将消息发送给名单上的所有客户端。
查看订阅信息
PUBSUB命令是Redis 2.8新增加的命令之一,客户端可以通过这个命令来查看频道或者模式的相关信息,比如某个频道目前有多少订阅者,又或者某个模式目前有多少订阅者。 PUBSUB CHANNELS[pattern] 这个命令用于返回服务器当前被订阅的频道(如果没有pattern参数,那么命令返回服务器当前被订阅的所有频道) PUBSUB NUMSUB PUBSUB NUMSUB[channel-1 channel-2…channel-n]子命令接受任意多个频道作为输入参数,并返回这些频道的订阅者数量。 PUBSUB NUMPAT PUBSUB NUMPAT子命令用于返回服务器当前被订阅模式的数量。 这个子命令是通过返回pubsub_patterns链表的长度来实现的,因为这个链表的长度就是服务器中,使用订阅模式订阅频道的客户端的数量。
第19章 事务
Redis可以使用事务来将多个命令打包成一条命令,然后一次性,按顺序地在服务端执行,在事务执行期间,服务器不会中断事务去执行其他客户端的命令请求。 以下是一个事务执行的过程,该事务首先以一个MULTI命令为开始,接着将多个命令放入事务当中,最后由EXEC命令将这个事务提交(commit)给服务器执行:
redis> MULTI
OK
redis> SET "name" "Practical Common Lisp"
QUEUED
redis> GET "name"
QUEUED
redis> SET "author" "Peter Seibel"
QUEUED
redis> GET "author"
QUEUED
redis> EXEC
1) OK
2) "Practical Common Lisp"
3) OK
4) "Peter Seibel
####事务的实现 #####事务的开始 MULTI命令的执行标志着事务的开始,MULTI命令可以将执行该命令的客户端从非事务状态切换至事务状态,这一切换是通过改变redisClient的flags属性中的REDIS_MULTI标识来完成的。 #####命令入队 当一个客户端处于非事务状态时,这个客户端发送的命令会立即被当一个客户端切换到事务状态之后,服务器会根据这个客户端发来的不同命令执行不同的操作: ·如果客户端发送的命令为EXEC、DISCARD、WATCH、MULTI四个命令的其中一个,那么服务器立即执行这个命令。 ·与此相反,如果客户端发送的命令是EXEC、DISCARD、WATCH、MULTI四个命令以外的其他命令,那么服务器并不立即执行这个命令,而是将这个命令放入一个事务队列里面,然后向客户端返回QUEUED回复。 服务器判断命令是该入队还是该立即执行的过程如下图所示: 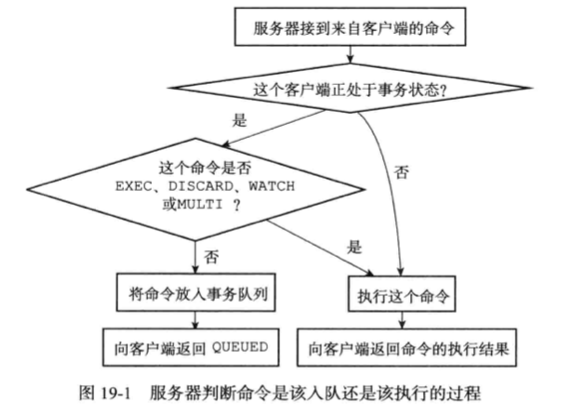
事务队列 redisClient中保存了自己的事务状态,这个事务状态保存在客户端状态的mstate属性里面:
typedef struct redisClient {
//事务状态
multiState mstate; /* MULTI/EXEC state */
// ...
} redisClient;
//事务状态包含一个事务队列,以及一个已入队命令的计数器(也可以说是事务队列的长度)
typedef struct multiState {
// 事务队列,FIFO顺序
multiCmd *commands;
// 已入队命令计数
int count;
} multiState;
//事务队列是一个multiCmd类型的数组,数组中的每个multiCmd结构都保存了一个已入队命令的相关信息,包括指向命令实现函数的指针、命令的参数,以及参数的数量:
typedef struct multiCmd {
// 参数
robj **argv;
// 参数数量
int argc;
// 命令指针
struct redisCommand *cmd;
} multiCmd;
事务队列以先进先出(FIFO)的方式保存入队的命令,较先入队的命令会被放到数组的前面,而较后入队的命令则会被放到数组的后面。 #####执行事务 当一个处于事务状态的客户端向服务器发送EXEC命令时,这个EXEC命令将立即被服务器执行。服务器会遍历这个客户端的事务队列,执行队列中保存的所有命令,最后将执行命令所得的结果全部返回给客户端。 #####WATCH命令的实现 WATCH命令是一个乐观锁(optimistic locking),它可以在EXEC命令执行之前,监视任意数量的数据库键,并在EXEC命令执行时,检查被监视的键是否至少有一个已经被修改过了,如果是的话,服务器将拒绝执行事务,并向客户端返回代表事务执行失败的空回复。 乐观锁与悲观锁 悲观锁就是假定最坏的情况,每次取数据时,都假设数据会被修改,所以取数据时都进行加锁,这样其他线程取数据时就会阻塞,直到获取到锁,然后取数据。java中的synchronized和ReentrantLock等独占锁就是悲观锁思想的实现。 乐观锁就是假定最好的情景,每次取数据时,都假设数据不会被修改,只有真正修改数据时会判断之前取到的值与变量当前在内存中的值是否一致,只有一致时才进行更新,否则就不更新。一般通过版本号或者CAS算法实现(CAS算法就是当且仅当当前内存中的的值等于预期值时,CAS通过原子方式用新值来更新内存中的值,否则不会执行任何操作(比较和替换是一个原子操作)。一般情况下是一个自旋操作,即不断的重试) 乐观锁适合写比较少的场景,悲观锁适合写比较多的场景。 乐观锁的缺点 1.ABA问题,就是变量先被改成B值,然后改成A值,JDK1.5的AtomicStampedReference的compareAndSet会判断对象的引用是否相同,相同才进行更新。 2. 循环时间长开销大,执行不成功会一直重试,长时间执行会给CPU带来压力 3.只能保证一个共享变量的原子操作,多个共享变量时 CAS 无效。但是JDK 1.5以后,提供了AtomicReference类来保证了引用对象之间的原子性,可以将多个变量放在同一个对象中,来保证原子性。 #####使用WATCH命令监视数据库键 每个Redis数据库都保存着一个watched_keys字典,这个字典的键是某个被WATCH命令监视的数据库键,而字典的值则是一个链表,链表中记录了所有监视相应数据库键的客户端。
typedef struct redisDb {
// 正在被WATCH命令监视的键
dict *watched_keys;
} redisDb;
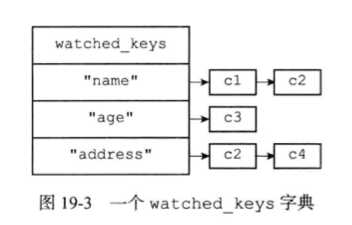
下图是一个watched_keys字典的示例,从这个watched_keys字典中可以看出: ·客户端c1和c2正在监视键”name”。 ·客户端c3正在监视键”age”。 ·客户端c2和c4正在监视键”address”。
监视机制的触发
所有对数据库进行修改的命令,比如SET、LPUSH、SADD、ZREM、DEL、FLUSHDB等等,在执行之后都会调用multi.c/touchWatchKey函数对watched_keys字典进行检查,查看是否有客户端正在监视刚刚被命令修改过的数据库键,如果有的话,那么touchWatchKey函数会将监视被修改键的客户端的REDIS_DIRTY_CAS标识打开,表示该客户端的事务安全性已经被破坏。
判断事务是否安全
当服务器接收到一个客户端发来的EXEC命令时,服务器会根据这个客户端是否打开了REDIS_DIRTY_CAS标识来决定是否执行事务: ·如果客户端的REDIS_DIRTY_CAS标识已经被打开,那么说明客户端所监视的键当中,至少有一个键已经被修改过了,在这种情况下,客户端提交的事务已经不再安全,所以服务器会拒绝执行客户端提交的事务,否则服务器将执行客户端提交的事务。 #####事务的ACID性质 在传统的关系式数据库中,常常用ACID性质来检验事务功能的可靠性和安全性。在Redis中,事务总是具有原子性(Atomicity)、一致性(Consistency)和隔离性(Isolation),并且当Redis运行在某种特定的持久化模式下时,事务也具有耐久性(Durability)。
原子性
事务具有原子性指的是,数据库将事务中的多个操作当作一个整体来执行,服务器要么就执行事务中的所有操作,要么就一个操作也不执行。 对于Redis的事务功能来说,事务队列中的命令要么就全部都执行,要么就一个都不执行,因此,Redis的事务是具有原子性的。 Redis的事务和传统的关系型数据库事务的最大区别在于,Redis不支持事务回滚机制(rollback),即使事务队列中的某个命令在执行期间出现了错误,整个事务也会继续执行下去,直到将事务队列中的所有命令都执行完毕为止。(原书作者认为,Redis事务的执行时错误通常都是编程错误产生的,所以没必要)
一致性
事务具有一致性指的是,如果数据库在执行事务之前是一致的,那么在事务执行之后,无论事务是否执行成功,数据库也应该仍然是一致的。Redis事务的一致性主要在于解决一些错误,防止事务执行破坏数据库。例如入队错误,执行错误,服务器停机。 服务器停机 如果Redis服务器在执行事务的过程中停机,那么根据服务器所使用的持久化模式,可能有以下情况出现: ·如果服务器运行在无持久化的内存模式下,那么重启之后的数据库将是空白的,因此数据总是一致的。 ·如果服务器运行在RDB模式下,那么在事务中途停机不会导致不一致性,因为服务器可以根据现有的RDB文件来恢复数据,从而将数据库还原到一个一致的状态。如果找不到可供使用的RDB文件,那么重启之后的数据库将是空白的,而空白数据库总是一致的。 ·如果服务器运行在AOF模式下,那么在事务中途停机不会导致不一致性,因为服务器可以根据现有的AOF文件来恢复数据,从而将数据库还原到一个一致的状态。如果找不到可供使用的AOF文件,那么重启之后的数据库将是空白的,而空白数据库总是一致的。 综上所述,无论Redis服务器运行在哪种持久化模式下,事务执行中途发生的停机都不会影响。
隔离性
事务的隔离性指的是,即使数据库中有多个事务并发地执行,各个事务之间也不会互相影响,并且在并发状态下执行的事务和串行执行的事务产生的结果完全相同。 因为Redis使用单线程的方式来执行事务(以及事务队列中的命令),并且服务器保证,在执行事务期间不会对事务进行中断,因此,Redis的事务总是以串行的方式运行的,并且事务也总是具有隔离性的。
耐久性
事务的耐久性指的是,当一个事务执行完毕时,执行这个事务所得的结果已经被保存到永久性存储介质(比如硬盘)里面了,即使服务器在事务执行完毕之后停机,执行事务所得的结果也不会丢失。
第 21 章 排序
在Redis中使用SORT命令可以对列表键、集合键或者有序集合键的值进行排序。
SORT命令的实现
SORT命令为每个被排序的键都创建一个与键长度相同的数组,数组的每个项都是一个redisSortObject结构,obj指针会指向列表或集合中的单个元素,score代表分值,根据score来对数组进行排序(因为涉及到字符串的排序及其他复杂情况,所以才单独使用score存储分值,而不是直接取元素的值) 以下是redisSortObject结构的完整定义:
typedef struct _redisSortObject {
// 被排序键的值
robj *obj;
// 权重
union {
// 排序数字值时使用
double score;
// 排序带有BY选项的字符串值时使用
robj *cmpobj;
} u;
} redisSortObject;
服务器执行SORT命令的步骤: 1)创建一个和numbers列表长度相同的数组,该数组的每个项都是一个redis.h/redisSortObject结构,如图所示

2)遍历数组,将各个数组项的obj指针分别指向numbers列表的各个项,构成obj指针和列表项之间的一对一关系,如图21-2所示。 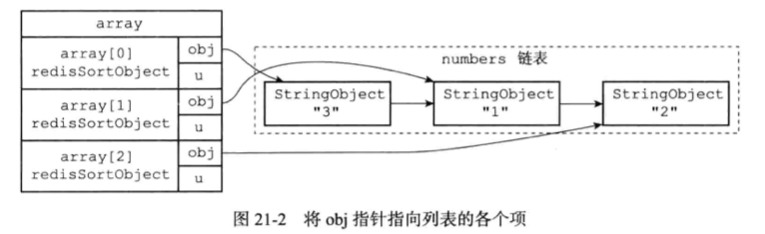
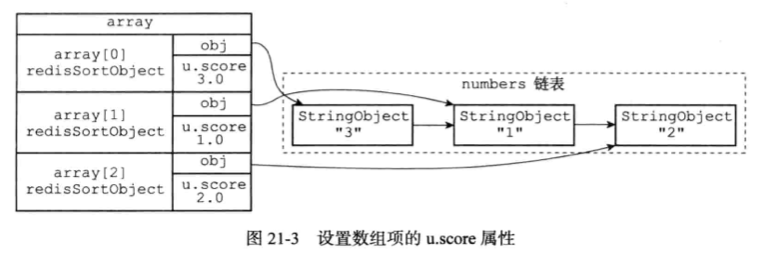
3)遍历数组,将各个obj指针所指向的列表项转换成一个double类型的浮点数,并将这个浮点数保存在相应数组项的u.score属性里面,如图所示。
 4)根据数组项u.score属性的值,对数组进行数字值排序,排序后的数组项按u.score属性的值从小到大排列,如图所示。
4)根据数组项u.score属性的值,对数组进行数字值排序,排序后的数组项按u.score属性的值从小到大排列,如图所示。 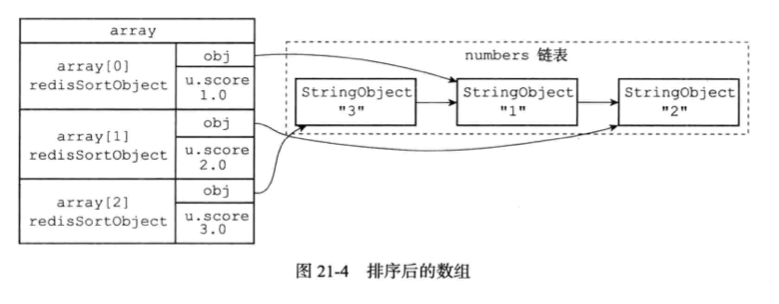
5)遍历数组,将各个数组项的obj指针所指向的列表项作为排序结果返回给客户端,程序首先访问数组的索引0,返回u.score值为1.0的列表项”1”;然后访问数组的索引1,返回u.score值为2.0的列表项”2”;最后访问数组的索引2,返回u.score值为3.0的列表项”3”。
ALPHA选项的实现
通过使用ALPHA选项,SORT命令可以对包含字符串值的键进行排序,会根据字母表的顺序来对键进行排序。
ASC选项和DESC选项的实现
在默认情况下,SORT命令执行ASC升序排序,排序后的结果按值的大小从小到大排列。ASC升序排序和DESC降序排序都由相同的快速排序算法执行,它们之间的不同之处在于: ·在执行升序排序时,排序算法使用的对比函数产生升序对比结果。 ·而在执行降序排序时,排序算法所使用的对比函数产生降序对比结果。
BY选项的实现
通过使用BY选项,SORT命令可以指定某些字符串键,或者某个哈希键所包含的某些域(field)来作为元素的权重,对一个键进行排序。 以下这个例子就使用苹果、香蕉、樱桃三种水果的价钱,对集合键fruits进行了排序,排序时会根据BY选项所给定的模式*-price,查找相应的权重键,例如对于”apple”元素,查找程序返回权重键”apple-price”。
redis> MSET apple-price 8 banana-price 5.5 cherry-price 7
OK
redis> SORT fruits BY *-price
1) "banana"
2) "cherry"
3) "apple”
#####LIMIT选项的实现 可以通过LIMIT选项,我们可以让SORT命令只返回其中一部分已排序的元素。 LIMIT选项的格式为LIMIT: ·offset参数表示要跳过的已排序元素数量。 ·count参数表示跳过给定数量的已排序元素之后,要返回的已排序元素数量。
GET选项的实现
通过使用GET选项,我们可以让SORT命令在对键进行排序之后,根据被排序的元素,以及GET选项所指定的模式,查找并返回其他键的值。 #####STORE选项的实现 在默认情况下,SORT命令只向客户端返回排序结果,而不保存排序结果:
redis> SADD students "peter" "jack" "tom"
(integer) 3
redis> SORT students ALPHA
1) "jack"
2) "peter"
3) "tom"
但是,通过使用STORE选项,我们可以将排序结果保存在指定的键里面,并在有需要时重用这个排序结果。 #####选项的执行顺序 如果按照选项来划分的话,一个SORT命令的执行过程可以分为以下四步: 1)排序:在这一步,命令会使用ALPHA、ASC或DESC、BY这几个选项,对输入键进行排序,并得到一个排序结果集。 2)限制排序结果集的长度:在这一步,命令会使用LIMIT选项,对排序结果集的长度进行限制,只有LIMIT选项指定的那部分元素会被保留在排序结果集中。 3)获取外部键:在这一步,命令会使用GET选项,根据排序结果集中的元素,以及GET选项指定的模式,查找并获取指定键的值,并用这些值来作为新的排序结果集。 4)保存排序结果集:在这一步,命令会使用STORE选项,将排序结果集保存到指定的键上面去。 5)向客户端返回排序结果集:在最后这一步,命令遍历排序结果集,并依次向客户端返回排序结果集中的元素。
第 22 章 二进制位数组
位数组是一个数组,数组元素是一个二进制位,在Redis中可以使用字符串对象来代表二进制位数组,字符串对象是一个SDS结构,SDS结构的buf是一个char数组,数组的每一位是一个char字符,每个char字符是8位。 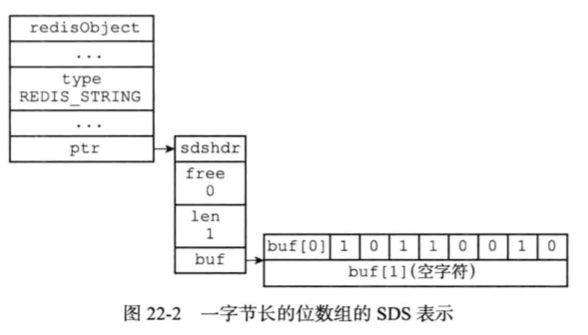
#####GETBIT命令的实现 GETBIT命令用于返回位数组bitarray在offset偏移量上的二进制位的值。 GETBIT命令的执行过程如下: 1)计算byte= offset÷8」,byte值记录了offset偏移量指定的二进制位保存在位数组的哪个字节。 2)计算bit=(offset mod 8)+1,bit值记录了offset偏移量指定的二进制位是byte字节的第几个二进制位。 3)根据byte值和bit值,在位数组bitarray中定位offset偏移量指定的二进制位,并返回这个位的值。
SETBIT命令的实现
同理,SETBIT用于将位数组bitarray在offset偏移量上的二进制位的值设置为value,并向客户端返回二进制位被设置之前的旧值。 #####BITCOUNT命令的实现 BITCOUNT命令用于统计给定位数组中,值为1的二进制位的数量。 实现BITCOUNT命令可能使用的几种算法进行介绍: 1.遍历算法,对每个位进行遍历,统计1的个数,时间复杂度为O(N) 2.查表算法,因为8个二进制位的1和0的排列方式是有限的,可以进行建表,将所有情况进行计算好。然后每次获取8个二进制位,然后进行查表比对,获取到这8个二进制位中1的个数。时间复杂度为O(N/8)。键长为8位的表如图所示,但是需要占用一定的内存空间来存储表。 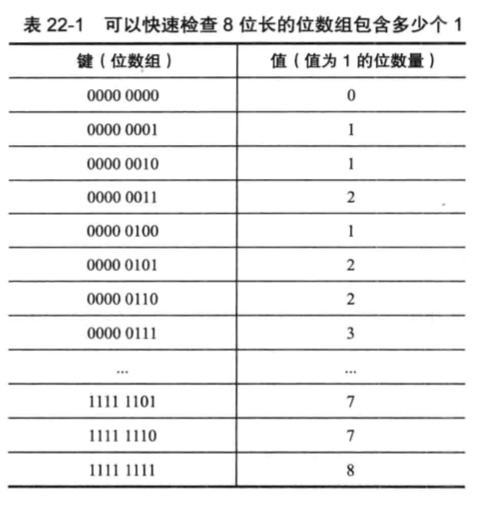
3.二进制位统计算法(3):variable-precision SWAR算法 “swar函数每次执行可以计算32个二进制位的汉明重量,它比之前介绍的遍历算法要快32倍,比键长为8位的查表法快4倍,比键长为16位的查表法快2倍,并且因为swar函数是单纯的计算操作,所以它无须像查表法那样,使用额外的内存。复杂度为O(N/32)。 “另外,因为swar函数是一个常数复杂度的操作,所以我们可以按照自己的需要,在一次循环中多次执行swar,从而按倍数提升计算汉明重量的效率: ·例如,如果我们在一次循环中调用两次swar函数,那么计算汉明重量的效率就从之前的一次循环计算32位提升到了一次循环计算64位。
Redis中BITCOUNT的实现 在执行BITCOUNT命令时,程序会根据未处理的二进制位的数量来决定使用那种算法: ·如果未处理的二进制位的数量大于等于128位,那么程序使用variable-precision SWAR算法来计算二进制位的汉明重量。在variable-precision SWAR算法方面,BITCOUNT命令在每次循环中载入128个二进制位,然后调用四次32位variable-precision SWAR算法来计算这128个二进制位的汉明重量。 ·如果未处理的二进制位的数量小于128位,那么程序使用查表算法来计算二进制位的汉明重量。
BITOP命令的实现
| 因为C语言直接支持对字节执行逻辑与(&)、逻辑或( | )、逻辑异或(^)和逻辑非(~)操作,所以BITOP命令的AND、OR、XOR和NOT四个操作都是直接基于这些逻辑操作实现的。 例如: |
BITOP AND result x y
使用BITOP命令对x和y进行与运算,并将结果保存在result键上。
第 23 章 慢查询日志
Redis的慢查询日志功能用于记录执行时间超过给定时长的命令请求,用户可以通过这个功能产生的日志来监视和优化查询速度。 服务器配置有两个和慢查询日志相关的选项: ·slowlog-log-slower-than选项指定执行时间超过多少微秒(1秒等于1 000 000微秒)的命令请求会被记录到日志上。 ·slowlog-max-len选项指定服务器最多保存多少条慢查询日志。如果满了会将最旧的慢查询日志删除。
第 24 章 监视器
通过执行MONITOR命令,客户端可以将自己变为一个监视器,实时地接收并打印出服务器当前处理的命令请求的相关信息。 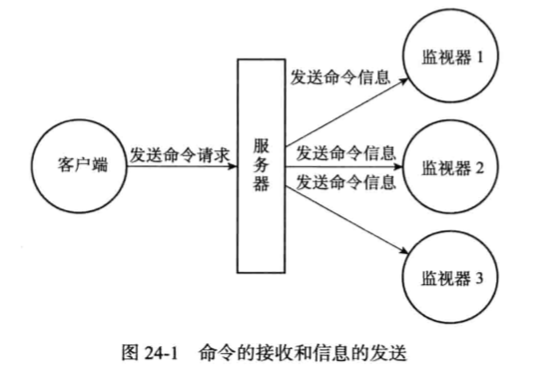
服务器收到MONITOR命令后,会将这个客户端的REDIS_MONITOR标志会被打开,并且这个客户端本身会被添加到monitors链表的表尾,之后服务器在每次处理命令请求之前,都会调用replicationFeedMonitors函数,由这个函数将被处理的命令请求的相关信息发送给各个监视器。