什么是一致性
CAP理论
对于一个分布式系统,不能同时满足以下三点:
一致性,可用性,分区容忍性
明确问题
数据不能存在单点上
分布式系统对容错(fault tolorence)的一般解决方案是多副本状态机(state machine replication)
多副本状态机:
多台机器具有完全相同的状态。
每个副本都会保存相同的操作日志,顺序执行,得到最终一致的结果。
共识算法就是用来解决 状态机日志复制的一致性问题
paxos其实是一个共识算法。系统的最终一致性,不仅需要共识,还取决客户端的行为。
主从同步
以最简单的两副本为例,首先来看看传统的主从同步方式。

写请求首先发送给主副本,主副本同步更新到其它副本后返回。这种方式可以保证副本之间数据的强一致性,写成功返回之后从任意副本读到的数据都是一致的。但是可用性很差,只要任意一个副本写失败,写请求将执行失败。

如果采用异步复制的方式,主副本写成功后立即返回,然后在后台异步的更新其它副本。

写请求首先发送给主副本,主副本写成功后立即返回,然后异步的更新其它副本。这种方式可用性较好,只要主副本写成功,写请求就执行成功。但是不能保证副本之间数据的强一致性,写成功返回之后从各个副本读取到的数据不保证一致,只有主副本上是最新的数据,其它副本上的数据落后,只提供最终一致性。

如果出现断网导致后台异步复制失败,则主副本和其它副本将长时间不一致,其它副本上的数据一直无法更新,直到网络重新连通。

如果主副本在写请求成功返回之后和更新其它副本之前宕机失效,则会造成成功写入的数据丢失,一致性被破坏。
Oracle:同步复制为最高保护模式 (Maximum Protection),异步复制为最高性能模式 (Maximum Performance),还有一种最高可用性模式 (Maximum Availability) 介于两者之间,在正常情况下,它和最高保护模式一样,但一旦同步出现故障,立即切换成最高性能模式。
传统的主从同步无法同时保证数据的一致性和可用性,此问题是典型的分布式系统中一致性和可用性不可兼得的例子,分布式系统中著名的CAP理论从理论上证明了这个问题。
而Paxos、Raft等分布式一致性算法则可在一致性和可用性之间取得很好的平衡,在保证一定的可用性的同时,能够对外提供强一致性,因此Paxos、Raft等分布式一致性算法被广泛的用于管理副本的一致性,提供高可用性。
多数派
基本思想:每次写入都保证写入大于N/2个节点,每次读都保证从大于N/2个节点读
问题:
并发环境下,无法保证系统的正确性,无法保证书顺序
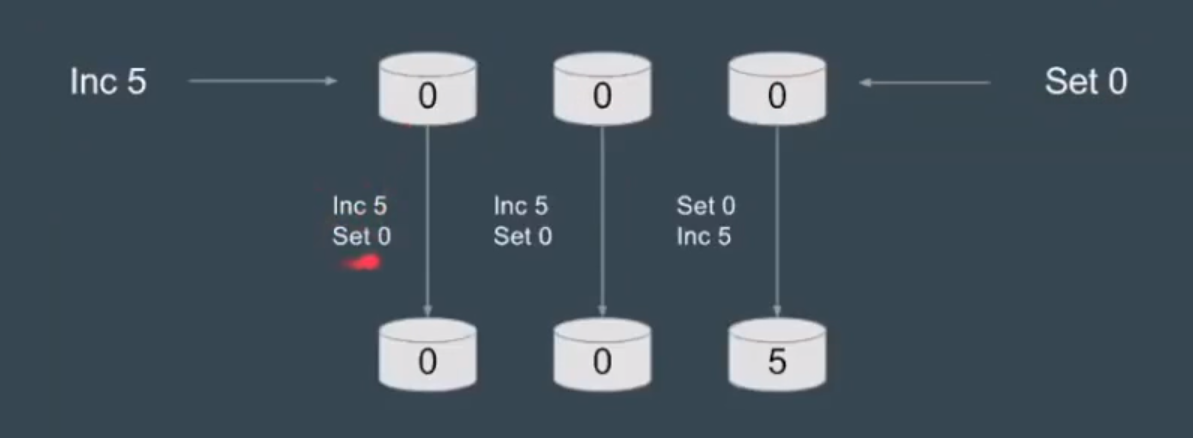
强一致算法
分布式的各个参与者达到最终一致的结果。通俗讲就是选举过程中,让不同的选民做出一致的决定
Paxos
自Paxos问世以来就持续垄断了分布式一致性算法,Paxos这个名词几乎等同于分布式一致性。Google的很多大型分布式系统都采用了Paxos算法来解决分布式一致性问题,如Chubby、Megastore以及Spanner等。开源的ZooKeeper,以及MySQL 5.7推出的用来取代传统的主从复制的MySQL Group Replication等纷纷采用Paxos算法解决分布式一致性问题。
Basic Paxos
Paxos的发明者是Lamport ,最初的描述使用希腊的一个小岛Paxos作为比喻,描述了Paxos小岛中通过决议的流程,
小岛按照民主的方式进行提议和表决,但没有人愿意把自己的全部精力时间放到这件事上,只会在一定时间进行投票,表决。
Paxos将系统中的角色分为:
客户端 (Client):系统的外部角色,请求发起者
提议者 (Proposer):提出议案
决策者 (Acceptor):参与决策
最终决策学习者 (Learner):不参与决策,从Proposers/Acceptors学习最新达成一致的提案(Value),备份。
Paxos算法一共三个阶段,通过一个决议分为两个阶段(Learn阶段之前决议已经形成)
-
Phase 1a: Prepare
proposer提出一个提案,编号为N,向所有的Acceptor发出请求。 必须大于之前proposer提出的提案编号。
-
Phase 1b: Promise
大于acceptor之前接受的提案编号则接受,返回promise,否则拒绝。
-
Phase 2a: Accept
如果达到多数派,proposer发出accept请求,包含提案编号N,以及提案内容。
-
Phase 2b: Accepted
如果此acceptor在此期间没有受到任何大于N的提案,则接受此提案内容,否则忽略。
基本流程:
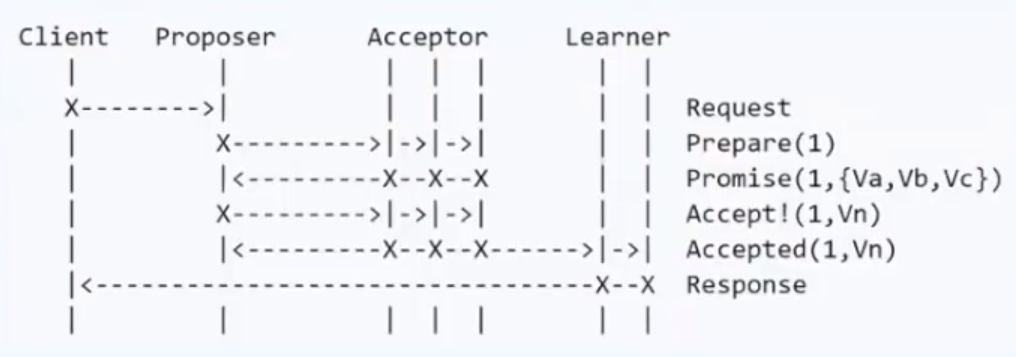
部分节点失败但达到多数派:

Proposer失败:
潜在问题活锁:
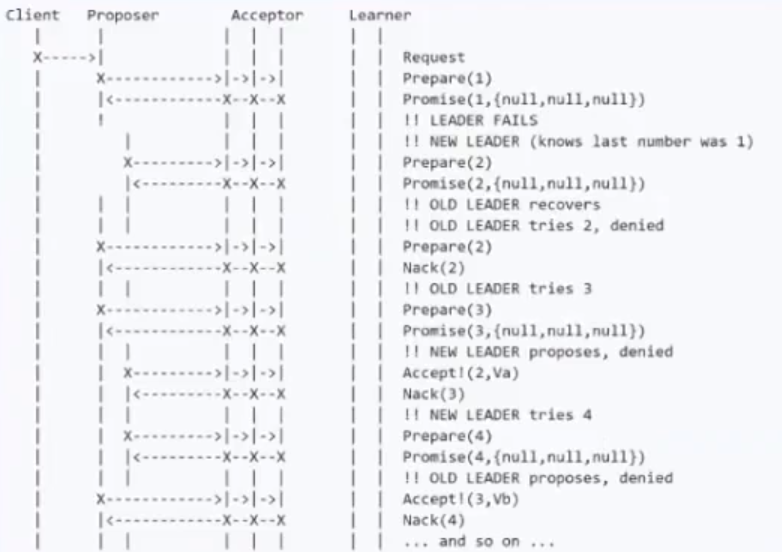
解决方案:生成一个随机的timeout
Basic Paxos存在的问题
难实现,效率低(2轮RPC),活锁
Mutli Paxos
新概念:Leader:唯一的Propser,所有请求都须经过此Leader
基本流程:

减少角色,进一步简化:

Raft
Mutli Paxos的一种,简单版本
划分成三个子问题
-
Leader 选举 timeout控制选举
- Log 复制
- Safety 所有的操作中,集群的共识一直是一致的,没有存在错误
重新定义了角色
- Leader
- Follower
- Candidate 临时的,当没有leader时,竞选Leader
原理动画解释:http://thesecretlivesofdata.com/raft/
场景测试:https://raft.github.io/
Leader 选举
1. After the election timeout,If followers don't hear from a leader then they can become a candidate
2. The candidate vote for itself and then requests votes from other nodes .
3. Nodes will reply with their vote.
4. The candidate becomes the leader if it gets votes from a majority of nodes.
- timeout结束,如果follower没有收到leader的心跳,那么他们可以成为候选人
- 然后候选节点为自己投票并请求其他节点的投票。
- 节点将用它们的投票进行回复,并重新开始timeout
- 如果候选人获得多数节点的选票,他就成为领袖。
平票:使用随机的timout
Log 复制
1. All changes to the system now go through the leader.
2. Each change is added as an entry in the node's log.
3. This log entry is currently uncommitted so it won't update the node's value.
4. To commit the entry the node first replicates it to the follower nodes...
5. then the leader waits until a majority of nodes have written the entry.
6. The entry is now committed on the leader node and the node state is "5".
7. The leader then notifies the followers that the entry is committed.
-
所有对系统的写操作都要经过leader。
- 每个更改都作为节点日志中的一个条目添加。
-
该日志条目目前未提交,因此它不会更新节点的值。
-
为了提交条目,节点首先将其复制到跟随节点。
-
然后leader等待,直到大多数节点都写入了条目。
-
leader节点提交。
- 然后,leader通知followers提交。
大致分为两个阶段:
第一阶段:写入日志
第二阶段:达到多数派, 提交
Safety
Leader失败,重新选举
分区
Raft能够在网络分区中保持一致性
让我们添加一个分区来区分a和B和C, D和E
由于分区,我们现在有了两位不同任期的领导人。
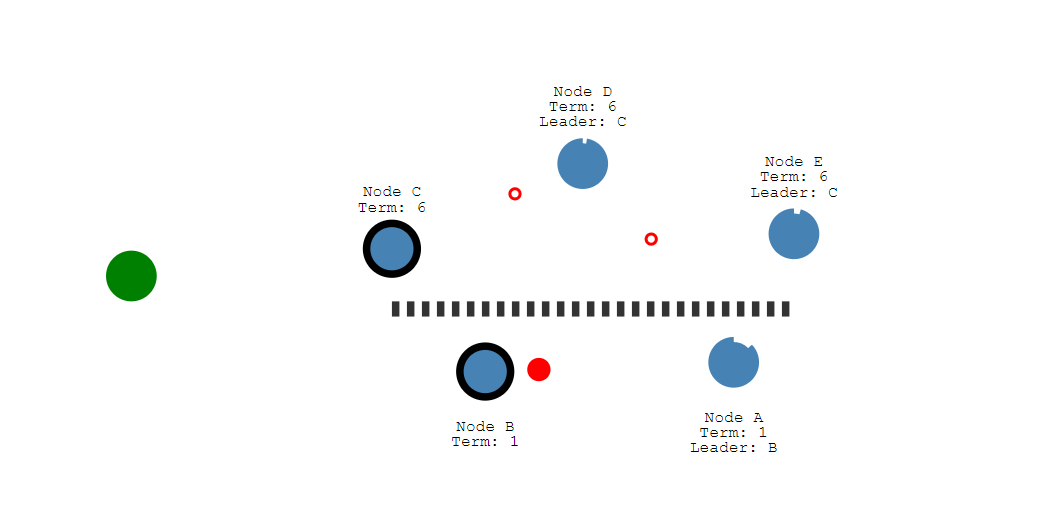
让我们添加另一个客户端,并尝试更新两个leader。
节点B无法复制到大多数节点,因此它的日志条目保持未提交状态
另一个客户端将尝试将节点C的值设置为“8”
这将会成功,因为它可以复制到大多数。
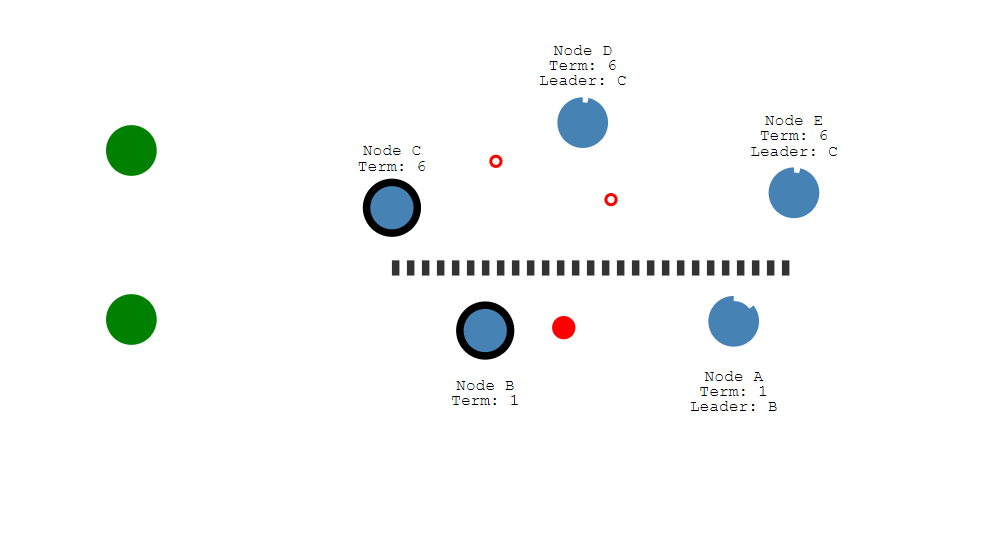
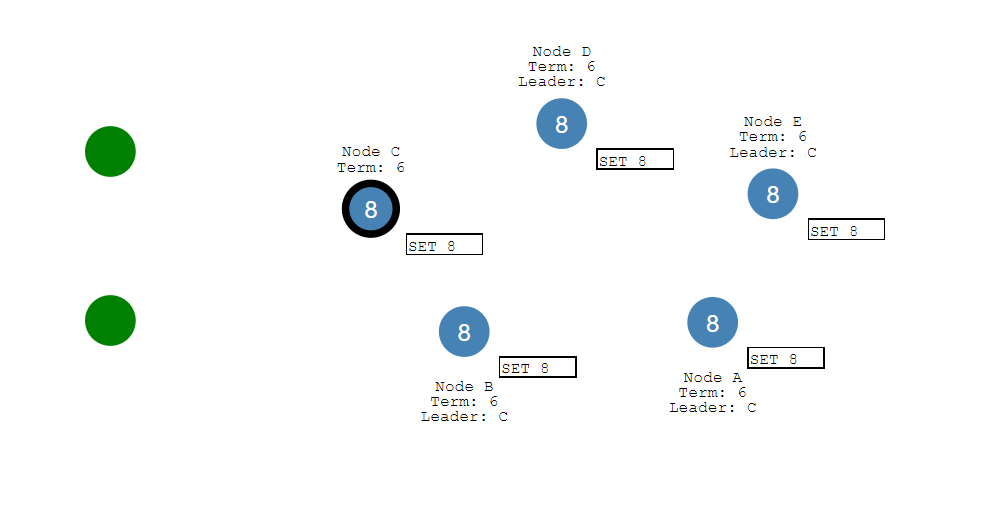
当分区恢复后
节点B将看到更高的选举任期 下台
两个节点A和B都将回滚它们的未提交条目,并匹配新leader的日志。
paxos其实是一个共识算法。系统的最终一致性,不仅需要共识,还取决客户端的行为。
一致性并不代表完全正确性
三个可能结果:成功,失败,unknown或者timeout
Raft 5 nodes example:
leader向follower同步日志,此时集群中3个节点失败,2个节点存活,结果是?
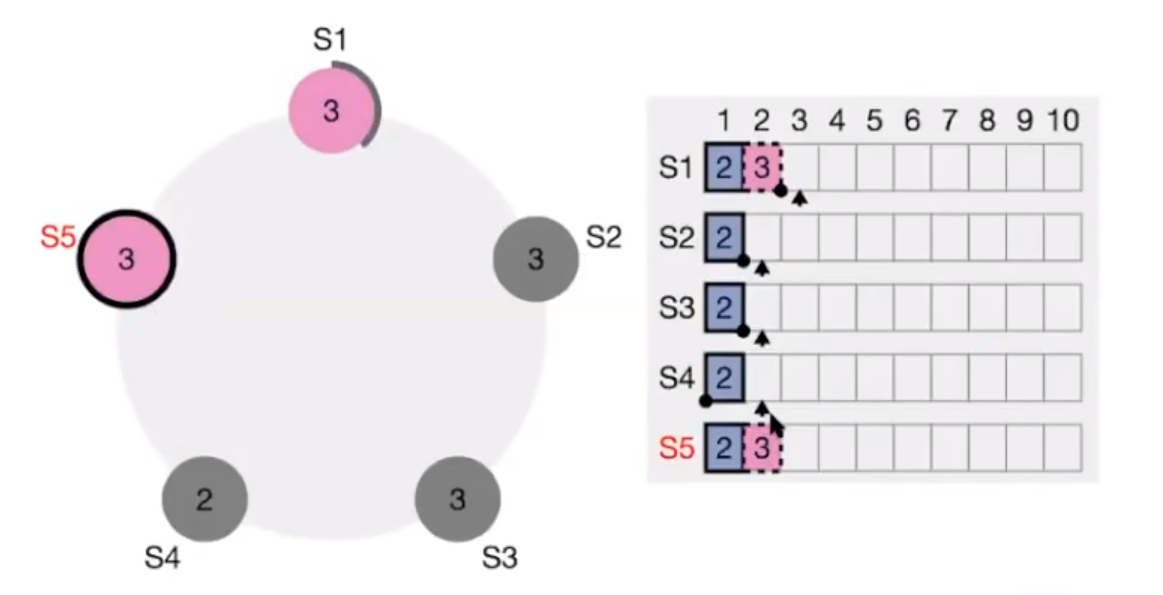
可能一:
返回客户端unknow或者timeout
S2,S3,S4恢复后,写入成功
可能二:
返回客户端unknow或者timeout
S2,S3,S4恢复后,S1,S5宕机,
新请求和之前的冲突
S1,S5恢复后 写入失败
返回unknow或者timeout时,要客户端自行处理。
ZAB
基本与raft一致
某些名词的叫法有一些区别:如ZAB将某一个leader的周期称为epoch,而raft则称为term
实现上有些不同: 如raft保证日志连续性,心跳方向为leader至follower。ZAB则是相反
应用场景:zookeeper
常见问题:
怎么解决脑裂?
什么是脑裂,就是一个大脑分成多个。也就是同时存在多个可用的leader,造成多个集群对外提供服务
当分区恢复,数据冲突,一致性遭到破坏。
解决方案:多数派机制
参考: